相对表达量前期数据过滤
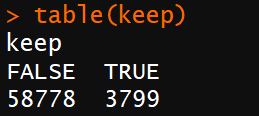
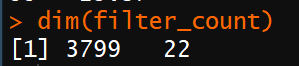
未处理的数据由于read counts数值过低
导致转换为FPKM和TPM的值也过低,我的数据预测的非编码有6万多个,但是大多表达量低,需要进行过滤
1 | rm(list=ls()) |

1 | #过滤平均Tpm<10的表达值 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WSZ@blog!

评论
未处理的数据由于read counts数值过低
导致转换为FPKM和TPM的值也过低,我的数据预测的非编码有6万多个,但是大多表达量低,需要进行过滤
1 | rm(list=ls()) |
1 | #过滤平均Tpm<10的表达值 |